作为一个 Java 选手,初学 Go 看到指针时,不禁回想起了大一那年被 C++ 指针支配的恐惧。最初对指针的用法有过不少误解和疑惑,某一天写代码时顿悟了,突然理解这些奇奇怪怪的用法是干嘛的了。
先从 Go 参数传递说起,这是指针最基础的用法之一。
需要传递引用时 对于任何一门语言,函数调用时传值还是传引用,是学习初期就要搞懂的,比如 Java 语言选手在学习之初都逃不开一个叫 swap 的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Main public static void main (String[] args) int i = 1 ; int j = 2 ; swap(i, j); System.out.println(String.format("函数外交换后的结果:%d,%d" , i, j)); } public static void swap (int a, int b) int tmp = a; a = b; b = tmp; System.out.println(String.format("函数内交换后的结果:%d,%d" , a, b)); } }
1 2 函数内交换后的结果:2,1 函数外交换后的结果:1,2
把两个数字传递到函数内部做交换操作,内部确实被交换了,但外部的两个变量在执行了 swap 函数后没有发生变化,原因就是 Java 的基本类型在参数传递时传值的。解决方法也很简单,传入将两个数字作为数组的元素或者对象的字段,传入数组或对象进行操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Main public static void main (String[] args) int [] array = {1 , 2 }; swap(array); System.out.println("函数外交换后的结果:" + Arrays.toString(array)); } public static void swap (int [] nums) int tmp = nums[0 ]; nums[0 ] = nums[1 ]; nums[1 ] = tmp; System.out.println("函数内交换后的结果:" + Arrays.toString(nums)); } }
1 2 函数内交换后的结果:[2, 1] 函数外交换后的结果:[2, 1]
这里不用 Go 做“示例一”的演示了,只看 Go 如何处理这种情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func main () a := 1 b := 2 ap := &a bp := &b fmt.Println("函数外指针指向的地址:" , ap, bp) swap(ap, bp) fmt.Printf("函数外交换后:%d,%d\n" , a, b) } func swap (p1 *int , p2 *int ) fmt.Println("函数内指针指向的地址:" ,p1,p2) tmp := *p1 *p1 = *p2 *p2 = tmp fmt.Printf("函数内交换后:%d,%d\n" , *p1, *p2) }
1 2 3 4 函数外指针指向的地址: 0xc0000b2268 0xc0000b2290 函数内指针指向的地址: 0xc0000b2268 0xc0000b2290 函数内交换后:2,1 函数外交换后:2,1
为了看得明显一点,我把指针指向的地址也打印了出来,因为传入的指针 p1、p2 指向了 a、b 地址,在 swap 函数中,我们是用了 *p1 和 *p2 来操作,即直接操作 0xc0000b2268、0xc0000b2290 对应的内存块的值,所以函数内的操作也会反映到函数外的 a、b 上去。
定义结构体方法/函数时 只要熟悉了上一节的内容,理解这个用法应该不难,主要是为了在方法中修改对象字段可以作用在对象本身上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func main () person := &Person{ name: "qiyuanfeng" , age: 18 , email: "xxxx@xxxx.xx" , address: "深圳市南山区" , } fmt.Println(person) person.changeName("fengqiyuan" ) fmt.Println(person) } type Person struct { name string age int email string address string } func (person *Person) changeName (name string ) person.name = name }
1 2 &{qiyuanfeng 18 xxxx@xxxx.xx 深圳市南山区} &{fengqiyuan 18 xxxx@xxxx.xx 深圳市南山区}
可以看到,调用对象的 changeName 函数修改 name 字段,成功作用在了对象本身上。如果在定义函数时不使用 *Person ,那么这个修改将不会起作用。所以如果结构体的函数需要对结构体做修改,则使用指针类型,如果不需要,则可以不使用指针类型。
大对象拷贝或传递 使用初期,在项目中见到了很多指针的用法,让我很不解。比如:
1 2 3 4 func handler1 (p Person) func handler2 (p *Person) func handler3 (a int ) *Person func handler4 (a int ) Person
再比如:
1 2 3 var personList1 []Personvar personList2 []*Personvar personList2 *[]*Person
刚开始看的懵,这几种写法有区别么?感觉用哪个都一样啊。
其实是因为进行拷贝操作时,比如参数传递,赋值操作等,传递地址比传递整个对象要方便得多,如下示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func main () person := &Person{ name: "qiyuanfeng" , age: 18 , email: "xxxx@xxxx.xx" , address: "深圳市南山区" , } fmt.Println(unsafe.Sizeof(person)) fmt.Println(unsafe.Sizeof(*person)) } type Person struct { name string age int email string address string }
这么一个简单的结构体构造出的对象,它本身有 56 个字节大小,而其地址仅 8 字节。设想如果是一个很大的对象,可能有成千上万个字节,进行拷贝操作,肯定会一定程度上影响性能。知道这一点后,上面的几种写法就很容易理解了:
传参数时如果传地址,就不会拷贝整个对象;
返回值如果使用地址,就不用在赋值操作时拷贝整个对象;
列表中保存地址([]*Person),那么这个列表的大小将大大减少,如果还是觉得大,还可以传递列表的地址(*[]*Person);
当然,也不能盲目地传地址,例如你在函数内做了修改,也会影响函数外的原对象,但你不想影响原对象,这个时候就不能拿地址传进函数喽,要按需使用。
扩展:Go 语言参数传递 看了上面关于传递引用的描述,也不要被迷惑了。
Go 中函数传递的本质是拷贝,传递的总是原来这个东西的一个副本,一个拷贝。 指针也只是一种数据类型而已!我们虽然传递了 *int ,其实传递的是这个指针的一份拷贝,又为这个拷贝赋予了原指针的值。 也就是说,Go 中所有传递的本质都是值传递。
下面看这个例子,我把函数外的 ap、bp 指针地址和传入函数内的 p1、p2 指针地址打印出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func main () a := 1 b := 2 ap := &a bp := &b fmt.Println("函数外指针的地址:" , &ap, &bp) swap(ap, bp) fmt.Printf("函数外交换后:%d,%d\n" , a, b) } func swap (p1 *int , p2 *int ) fmt.Println("函数内指针的地址:" , &p1, &p2) tmp := *p1 *p1 = *p2 *p2 = tmp fmt.Printf("函数内交换后:%d,%d\n" , *p1, *p2) }
1 2 3 4 函数外指针的地址: 0xc000010028 0xc000010030 函数内指针的地址: 0xc000010040 0xc000010048 函数内交换后:2,1 函数外交换后:2,1
虽然指针指向的地址是一样的,但函数内外指针本身的地址不一样了,说明函数传参对于指针来说,也只是传递了指针的一个拷贝。用面向对象的说法讲,传递对象 ap 时,新建了一个对象 p1,并将 p1 指向 ap 的地址,p1 和 ap 并不是同一个对象,但指向了同一块内存。
事实上,在 Java 中使用数组和对象等进行所谓“引用传递”时,也是这样的做法,并没有真正传递引用,而是传递了一个对象的拷贝。
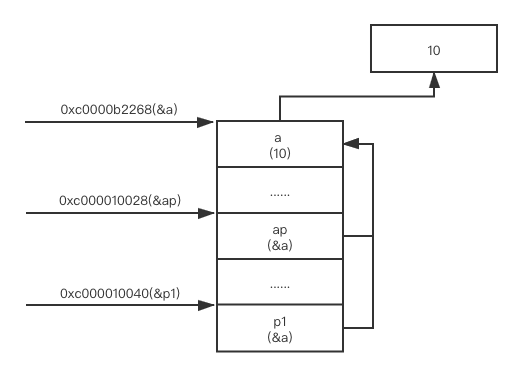
下面这张图,以 a、ap、p1 为例,说明了他们之间的关系
上图中我画了个简单的内存模型图,左侧为内存地址(小括号中为这个地址对应的标记)右侧是四个内存块,其中 a 的值为 10,ap 和 p1 的值为 &a,即 a 内存块的地址。ap 和 p1 却又不是同一个内存块,正是因为 p1 是由 ap 复制而来的,而非真正的 ap。
在这一点上,指针传参的本质与直接传参的本质是一样的,都是对值的复制,只是指针的值是内存地址而已。
关于 Map、Channel、Slice 的迷惑 了解清楚了 Go 的参数传递,但大家常说,map、chan、slice 是引用传递,对于这三种类型来说,好像并不太符合我们上面的说法,因为我们无需传指针就可以同步修改函数外的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func main () persons:=make (map [string ]int ) persons["张三" ] = 10 fmt.Printf("函数外map的内存地址是:%p\n" , &persons) modify(persons) fmt.Printf("函数外,修改map后的值:%v\n" ,persons) } func modify (p map [string ]int ) fmt.Printf("函数里接收到map的内存地址是:%p\n" , &p) p["张三" ] = 20 fmt.Printf("函数内,修改map后的值:%v\n" ,p) }
1 2 3 4 函数外map的内存地址是:0xc000010028 函数里接收到map的内存地址是:0xc000010038 函数内,修改map后的值:map[张三:20] 函数外,修改map后的值:map[张三:20]
函数内外的 map 的内存地址并不一样! 说明这也是一个值传递。那么函数内是如何影响了函数外的 map 呢?
看一看 makemap 的源码,这个函数是使用 make 创建 map 所调用的底层函数。
1 2 3 func makemap (t *maptype, hint int , h *hmap) *hmap ...... }
可以看到,使用 make 函数创建的 map 返回的是 *hmap,也就是说,persons:=make(map[string]int) 中,persons 实质上是一个 *hmap 的指针,这也解释了为什么我们只传入 persons 也能修改外面的 map,也就意味着,persons 内存储的实质上是一个内存地址,只是 Go 语言帮我们做了处理,我们打印时看到的是 map[张三:20] 这种形式。那么我们使用 %p 强行打印 persons 地址看看,如果它不是一个地址,那么会无法正常显示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func main () persons:=make (map [string ]int ) persons["张三" ] = 10 fmt.Printf("函数外map的内存地址是:%p\n" , persons) modify(persons) fmt.Printf("函数外,修改map后的值:%v\n" ,persons) } func modify (p map [string ]int ) fmt.Printf("函数里接收到map的内存地址是:%p\n" , p) p["张三" ] = 20 fmt.Printf("函数内,修改map后的值:%v\n" ,p) }
1 2 3 4 函数外 map 的内存地址是:0xc00009a750 函数里接收到map的内存地址是:0xc00009a750 函数内,修改map后的值:map[张三:20] 函数外,修改map后的值:map[张三:20]
使用上面示例七几乎同样的代码,只是把 &persons 和 &p 去掉了 &。结果是,可以打印出来,而且所指向的内存地址一致。channel 与 map 同理。
但 slice 的原理不一样,slice 的本质是一种结构体+元素指针的混合类型。
关于 slice 我还没有深入了解,暂且不提。
参考文献 Go语言参数传递是传值还是引用